 轉載于 《保密科學技術》雜志 2022年5月刊
轉載于 《保密科學技術》雜志 2022年5月刊
作者:
方 涵 張衛明 張志翔 田 輝 王志倫
中國科學技術大學
合肥高維數據技術有限公司
安徽省保密局
【摘要】設計出一種能夠抵抗屏攝信道傳輸的數字水印算法是解決屏攝泄密問題的迫切需求。針對此需求,本文總結了多個可應用于屏攝泄密場景的數字水印技術,從技術發展的角度分別對關鍵算法進行介紹。同時,通過實驗總結了現有屏攝溯源技術的優劣,并對這一研究課題進行了展望。
【關鍵詞】屏攝溯源 數字水印 魯棒性 不可見性
【中圖分類號】 TP393.08 ;TP309
【文獻標識碼】 A
1、引言
數字水印技術是通過一定的算法在待保護的數字多媒體載體(圖像、文檔、音頻、視頻等)中嵌入含有身份標識的秘密信息(數字水印),從而使得數字多媒體載體包含有一種附加信息的功能。而水印信息的嵌入不易被人眼所察覺,也不會對原始載體本身的使用產生影響。最重要的是,它不能夠被輕易擦除與破壞。因而,數字水印最常被應用于版權信息認證與失泄密文件追蹤。
智能手機性能的提升使信息傳輸有了新手段,那就是通過手機拍照傳輸圖片來實現。使用手機對計算機屏幕進行拍照這一記錄方式能在保證內容質量的前提下很大程度抹除附加水印信號,給水印提取帶來新的難題。所以工業界對數字水印提出的新需求就集中體現數字水印需要具有“ 抗屏攝魯棒性”。近幾年來,通過手機偷拍并泄露公司敏感信息從而產生巨大商業損失的案例屢見不鮮,突破“抗屏攝魯棒性”難題,設計新一代數字水印技術,對于促進新媒體技術的產業應用和商業推廣具有重要意義。
近年來,具有屏攝魯棒性的數字水印算法逐漸被關注,但仍處于起步階段。因為相比于電子信道失真,如壓縮、濾波、加噪等圖像處理失真, 屏攝失真更為復雜和隨機。電子信道失真能通過數字計算有效地進行模擬,從而可以進行深入分析,針對性地設計出相應的算法來解決問題。而對于屏攝過程,多媒體內容的復制與傳輸由原始的電子信道傳輸變為真實的空氣信道傳輸,失真產生于屏幕拍照過程。這種跨媒介傳輸過程引入的失真極為復雜,包括伽馬變換、JPEG壓縮、 透視失真等一系列復雜失真,不可簡單使用已知圖像處理過程進行建模,不易進行定量分析。相對于傳統的圖像處理失真,屏攝傳輸對多媒體內容的改變更大,這也意味著對水印魯棒性的要求更高,傳統的針對電子信道的魯棒水印算法已經不能有效解決這種場景下的問題。如何有針對性地通過數字算法的設計,達到屏攝魯棒性的需求,成為現階段數字水印領域熱點問題。

2、屏攝水印技術研究進展
2.1 基于傳統特征的水印算法
目前大多數屏攝魯棒水印算法都是基于傳統特征設計的。在屏攝魯棒水印之前,學術論文更關注的是打印拍照的魯棒性。Nakamura 等[ 1 ] 在2004年首先提出了一種滿足打印拍照魯棒性的水印算法,通過設計正交的模板圖案表達“ 0 / 1 ”比 特,再以疊加的方式嵌入水印圖像中,保證水印信號在打印拍照前后的一致性 。之后 ,Primila 等發表了多篇文章 [ 2 - 4 ] 關注打印拍照的魯棒性,但原理與參考文獻[ 1 ] 相似,都是通過設計不同的模板表達水印消息,實現屏攝魯棒的效果, 但其針對性地設計了預處理和后處理算法,使水印能更好地被嵌入和提取。Fang 等 [ 5 ] 在2018年以 “ 屏攝魯棒水印 ”為題提出了一種屏攝魯棒溯源水印算法,這也是學術界第一次將屏攝失真作為重要失真進行分析。在參考文獻[ 5 ] 中,作者將屏攝過程中的主要失真分成了鏡頭失真、光照失真和摩爾紋失真3個方面,并通過對失真的分析,提出了一種基于尺度不變特征變換(SIFT)特征點結合離散余弦變換(DCT )的算 法,有效保證了數字水印在屏攝失真中的魯棒性 。除了SIFT特征, Chen等人 [ 6 ] 提出了一種基于加速穩健特征(SURF)和離散傅里葉變換 (DFT ) 的屏攝魯棒水印算法,通過對局部方形特征區域的傅里葉系數的調制,實現水印的嵌入。基于此算法,Chen等人[ 7 ] 又提出了一種結合圖像加密的屏攝魯棒水印算法,有效地將加密過程和水印過程融合,保證了有權限用戶的行為可追溯性。L i 等人[ 8 ] 提出了一種基于“ 超級點” ( Super Point )的特征定位算法,保證嵌入的特征點能在屏攝水印前后都被有效定位,再通過對傅里葉系數的調制實現水印的嵌入與提取。基于傳統特征的水印方案大多與圖片特征有關,包括特征定位和水印嵌入兩個步驟 。而Gugel mann 等人[ 9 ] 提出了一種在屏幕中添加水印的方案,通過使用明暗不同的圖形表達“ 0 / 1 ” 比特,并疊加在屏幕上實現水印的嵌入過程。
2.2 基于深度學習特征的水印算法
隨著深度學習技術在圖像處理各個環節中的應用,深度學習的特征提取能力已逐步被挖掘。近年來,也有多種基于深度學習特征的水印方法被提出。Zhu等人 [ 1 0 ] 首先提出了 “ 編碼器—噪聲層—解碼器” 的深度學習水印框架,通過在噪聲層中添加失真,實現特定的魯棒性。但這樣的方案不能保證不可導失真的魯棒性,所以為解決屏攝過程這一不可導失真的問題,出現了兩種典型思路。第一種是通過可導過程模擬屏攝失真,加入到噪聲層中進行訓練。Jia等 人 [ 1 1 ] 提出了一種模擬屏攝全過程的方案,包括幾何變換、噪聲、濾波、顏色變換等圖像處理操作,通過訓練的方式實現了對屏攝失真的魯棒性。另一種思路是將屏攝過程當作黑盒子,使用神經網絡模擬屏攝過程,再將模擬的網絡當作噪聲層加入到深度學習框架中進行訓練。Wengrowsk i 等人[ 1 2 ] 提出了一種 “ 屏攝轉換網絡” (CDTF),通過構建屏攝前后數據對能有效模擬屏攝過程并將此網絡加入到深度學習框架中進行訓練。這一算法對于深度學習框架而言也更為典型。
3、屏攝水印典型算法
本節分別介紹基于傳統特征的水印算法[ 5 ]和基于深度學習特征的水印算法[ 12 ]細節。
3.1 基于SIFT特征和DCT系數的屏攝魯棒水印算法
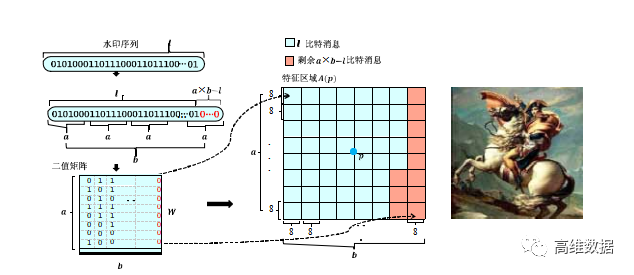
圖1 基于SIFT特征和DCT系數的屏攝魯棒水印算法嵌入過程示意圖
圖 1 展示了基于SIFT特征和DCT系數的屏攝魯棒水印算法[ 5 ] 的嵌入過程,主要步驟為:對版權信息進行處理,生成待嵌入的水印序列;利用SIFT特征點定位算法在載體圖像中定位及篩選出若干特征點,對特征點周圍的待嵌入區域通過頻域調制的方式將水印序列進行嵌入,生成含水印的圖像。下面對這一過程進行詳細介紹。
( 1 )對版權信息進行線性分組糾錯(BCH)編碼,并將其重構成 a × b 的二值矩陣W,得到待嵌入的水印序列,其中的 a 與 b 均為整數。
( 2 ) 對載體圖像進行預處理:若載體圖像為彩色圖像,則將RGB空間的圖像轉化為YCbCr空間的圖像,并將Y通道圖像作為待嵌入圖像 I ,若載體圖像為灰度圖,則直接將載體圖像作為待嵌入圖像I 。
( 3 ) 特征點定位:對于一張待嵌入圖像I ,通過下采樣得到采樣后的圖像 I o; 對圖像 I o 進行不同平滑程度的高斯濾波得到一系列濾波后圖像。進行高斯濾波時,高斯濾波核的方差決定了濾波平滑的程度。之后,對不同平滑程度的濾波圖像進行差分操作,得到一系列差分圖像, 記為高斯差分空間。
D( p )= D( x , y , σ )= L( x , y , kσ )- L( x , y , σ )
記 p = ( x , y , σ ) 為高斯差分空間中的點;對每個高斯差分空間中的點,均與以其自身為中心的3 × 3 × 3的立方體中除其自身之外的其余26個點進行對比,如果 D ( p ) 為其中的最大值或最小值,則認為 p是特征點。
( 4 )特征點篩選:每個水印比特需要使用 8 × 8 的像素去嵌入,待嵌入的水印序列為 a × b 的二值矩陣,將需要 ( a × b ) × ( 8 × 8 ) 大小的以特征點為中心的像素塊。由于嵌入區域不能重疊,需要對上個步驟得到的 n 個特征點進行篩選,篩選出特征點強度盡可能大 且不重疊的k 個區域作為候選嵌入區域,最終篩選出 k 個滿足要求的特征點 。
( 5 ) 對每一個特征點周圍的待嵌入區域 B,將其分成 a × b 個 8 × 8 的塊,針對每個塊對其進行離散余弦變換得到大小為 8 × 8 的離散余弦矩陣 D,取出中頻系 數C1 = D( 4 , 5 ) 和 C2 = D( 5 , 4 ),在嵌入水印時做如下處理:為待嵌入的水印比特。為了保證在經過手機壓縮過程后C1,C2仍然滿足設定的大小關系,增加冗余量d使其中d = | C 1 - C 2 | 。根據待嵌入的水印比特 w、JPEG壓縮表中對應的量化系數q1 和 q2 、嵌入強度 r 、中頻系數C1 和C2以及冗余量d計算嵌入量 。
在每個比特嵌入完成后,對塊進行離散余弦反變換, 完成嵌入過程,得到圖像 I E M ;若載體圖像為灰度圖像,則圖像 I E M 直接作為嵌入完成圖像;若載體圖像為彩色圖像,則將圖像 I E M 替換原有的Y 通道圖像并重構R G B 圖像作為嵌入完成圖像。
對于水印提取階段而言,當含水印的圖像被非法拍攝并流傳時,我們需要對屏攝圖像進行透視畸變校正,再通過裁剪方式獲取所需的圖像,之后,通過特征點定位算法定位出嵌入位置并使用交叉驗證的提取方法將水印序列進行提取,進而復原出版權信息。
( 1 ) 對于屏攝圖像 I '',我們需要進行透視畸變的校正,并裁剪出我們需要提取的圖像。
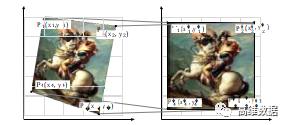
圖2 透視校正示意圖
圖2展示了透視畸變校正的過程,確定含水印的圖像的4個頂點在屏攝圖像 I ' ' 中的位置,4個頂點記為 P i ( x i , y i ) ,同時設置校正后預期的這4個點的位置為 P i ' ( x i ' , y i ' ) ,其中 i ∈ { 1 , 2 , 3 , 4 } ;根據這8個頂點位置求解出對應的8個變量a0 , b0 , a1 , b1 , c1 , a2 , b2 , c2 , 這8個變量決定了從失真圖像( 即屏攝圖像 I'' )到校正圖像的映射關系,計算出這 8 個變量后能形成一個從失真圖到校正圖之間像素一一對應的映射;之后通過校正后點的位置(即, P i ' ( x i ' , y i ' ) )裁剪出需要提取的圖像。
( 2 ) 對于裁剪得到的圖像,如果為灰度圖像,則利用SIFT特征點定位算法進行特征點定位及篩選;如果為彩色圖像轉化為YCbCr空間的圖像,并提取Y通道 圖像,再利用SIFT特征點定位算法進行特征點定位及篩選;特征點定位及篩選的方式與水印嵌入階段的方式相同,此時篩選出2k個特征點。
( 3 )對每一個特征點進行一個3 × 3 鄰域的遍歷,即對每一個特征點,需要對 9 個以該特征點及其鄰域點為中心的大小為( a × b ) × (8×8) 的區域進行提取操作 ;對于一張圖像,共提取2 × k × 9個區域。
對于每一個待提取的區域,將其分解成 a × b 個大小為 8 × 8 的像素塊;針對每個塊對其進行離散余弦變換得到大小為 8 × 8 的離散余弦矩陣 D ,取出中頻系數 C1 = D ( 4 , 5 ) 和 C2 = D ( 5 , 4 ) ,并根據中頻系數計算嵌入的水印比特w 。
對于一張圖像,一共提取出了 2 × k × 9個水印,記W q ( W q = [ w q1 , w q2 … w q9 ] ) 為由特征點p q提取出的水印組;從兩個不同的組W q 與 W r 中分別提取兩個水印 w qα 和 w rβ 作為一個水印對來進行比較, 然后記錄所有差別小于設定值th的水印對 w f ,如下述公式所示:得到 1 個水印對,每個水印對包括 2 個水印,故總共得到21個水印。
對于任一相同位置,如果21個水印中超過l個水印在該位置的水印值為1,則該位置水印值為1 ,否則認為該位置水印值為 0 。
( 4 ) 當提取出水印編碼后,將其重構成一維的序列,并通過BCH碼解碼復原出版權信息。
3.2 基于CDTF的深度學習屏攝魯棒水印算法
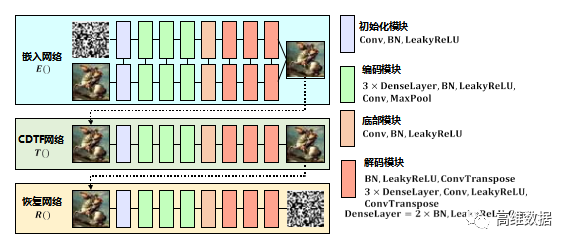
圖3 基于CDTF的深度學習屏攝魯棒水印框架
圖3展示的基于CDTF的深度學習屏攝魯棒水印 [ 1 2 ] 的 框架包括嵌入網絡E、CDTF網絡T和恢復網絡R。3個網絡串聯,組成完整的可端到端訓練的網絡。這3個網絡主要的構成如下所述。
( 1 ) 嵌入網絡E:嵌入網絡E的輸入是載體圖片和原始消息,嵌入網絡由兩支相同結構的子網絡組成,2個網絡共同作用,組合輸出含水印圖像。
( 2 ) CDTF網絡T:CDTF網絡的作用是模擬屏攝過程,通過預先采集的屏攝數據集先訓練一個屏攝模擬網絡,再將此網絡當作噪聲層加入到整個深度學習框架中進行訓練。CDTF網絡的輸入是含水印圖像,輸出是經過模擬屏攝過程后的失真圖像。
( 3 ) 恢復網絡R:恢復網絡的作用是從失真圖像中恢復出原始嵌入的消息,恢復網絡的輸入是失真圖像,輸出是原始水印信息。
整個網絡是端到端訓練的,訓練過程如下。
( 1 ) 屏攝數據集的獲取:在訓練嵌入網絡和恢復網絡之前,我們需要預先訓練CDTF網絡,這一網絡代表了屏攝過程中的失真。所以第一步,我們首先需要通過真實拍攝過程獲得一個足夠數量的輸入和輸出屏攝數據對,用于訓練CDTF 網絡,數據對中屏攝后的圖像需要進行透視校正。
( 2 ) CDTF網絡的訓練:在得到屏攝數據集后,就可以進行CDTF網絡的訓練了。CDTF網絡的輸入為原始圖像,輸出為屏攝后圖像,通過設置相應的損失函數來實現網絡的訓練。
( 3 ) 嵌入網絡和恢復網絡的訓練:在CDTF 網絡訓練結束后,需要對嵌入網絡和恢復網絡進行訓練。這兩個網絡是端到端訓練的,在訓練過程中,需要固定住預訓練的CDTF網絡,只更新嵌入網絡和恢復網絡的參數,整個大網絡設置相應的損失函數進行約束。
4、實驗結果與分析
本節首先介紹上述2種算法的實現細節,包括數據集和屏攝設備等。同時展現算法嵌入水印后圖像的視覺質量,以及在不同角度、不同距離下的屏攝實驗結果。
4.1 實現細節
算法測試使用的數據集為USC - SIPI數據集,每一張圖片都被縮放至1 2 8 × 1 2 8 × 3 像素的大小,嵌入的水印容量為3 0比特。在訓練深度學習網絡時,使用的數據集為MS-COCO 數據集的 10000 張隨機圖像。屏攝使用的手機為“ HuaweiP30 Pro ” ,顯示器為“ LenovoLEN9053 ” 。評價視覺質量的指標為峰值信噪比PSNR 和結構相似度SSIM ,評價魯棒性的指標為比特錯誤率。
4.2 視覺質量

圖4 不同算法的視覺質量
我們首先用 4 張圖片展示利用 2 種算法生成的圖像的主觀視覺質量,如圖4所示。可以看出,兩種算法都保證了較高的視覺質量,但在某一些細節方面仍然存在視覺失真。
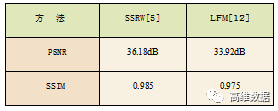
PSNR 和SSIM 的對比如表1所示,可以看出,參考文獻[ 5 ] 相較于參考文獻 [ 12 ] 有著一定的視覺質量優勢,可能的原因是參考文獻[5 ] 是選擇圖像中的一部分圖像塊進行嵌入,但參考文獻 [12] 卻是在原圖的所有部分進行嵌入,所以產生的視覺質量有一定的劣勢。
4.3 屏攝實驗結果
表1 不同方法的視覺質量對比
本節將分別從不同的屏攝距離、不同的屏攝角度進行屏攝實驗來驗證算法的屏攝魯棒性。屏攝距離選擇的是 20 - 60 cm ,角度選擇的是左40 ° 到右40 °,上40 ° 到下40 ° ,以10 °為一個間隔。實驗結果展示在表2、表3和表4中。
表2 不同距離下的屏攝魯棒性
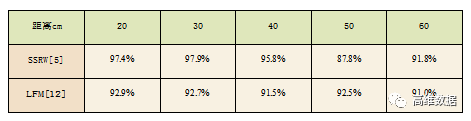
從表2中可以看出,對于不同的距離,兩種方法都有著一定的提取準確率,但總體而言,參考文獻 [ 5 ] 的方案保證了較高的提取準確率,在20 — 40cm 的情況下,準確率都大于95%,而在50 — 60cm的情況下,提取準確率在90%左右。對于參考文獻 [ 12 ] 的方案,準確率在所有距離下都穩定在91% 左右 。
表3 不同水平角度下的屏攝魯棒性

表4 不同垂直角度下的屏攝魯棒性

從表3和表4可以看出,兩種算法在大多數屏攝角度下都保持著高于90%的準確率,但是隨著屏攝角度的變大,準確率也有所下滑,這是因為屏攝角度變大產生的失真更為嚴重,從而進一步影響提取的準確性。
5、結語
本文主要從“ 屏攝魯棒性” 這一現實需求牽引的性質的角度出發,總結了現有數字水印算法在屏攝魯棒性的部分工作。由于屏攝過程的復雜性,設計屏攝魯棒的數字水印算法并非易事,能有效保證多角度屏攝下的魯棒水印更是難點問題。現階段的工作大多停留在以圖片為載體進行方案的設計,通過人工特征結合變換域系數的方法或通過深度學習訓練的方法查找可用特征并進行實驗。但在視覺質量和魯棒性兩方面仍存在一定的改進空間。
這里, 本文對后續水印算法可能的發展方向做出簡要闡述。
( 1 )基于圖像載體的屏攝魯棒水印方案有一個前提,那就是屏攝圖像中需要包含完整的電子圖像,當只拍攝了圖像的一部分時,算法就不能很好地保證魯棒性了,這一缺陷在基于圖像的算法中幾乎都存在。原因在于提取時需要對圖像進行透視畸變校正,而校正的前提就是使用圖像的四個頂點,所以僅拍攝了部分圖像時,就無法定位到4個頂點用于校正了。但在真實場景下,也有可能出現只拍攝一部分圖像的情況,那么如何針對部分屏攝圖像的場景,解決部分圖像的校正和提取問題,是一個重要的研究方向。
( 2 ) 深度學習的特征提取能力會因為神經網絡結構和訓練集的豐富程度變化而變化,如何更好地根據屏攝失真的特點有針對性地設計神經網絡結構,是優化提取端的重要任務。如何根據場景定制噪聲層也是實現神經網絡數字水印的重要一環。M
【參考文獻】
[1]Takao Nakamura, Atsushi Katayama, Masashi Yamamuro, Noboru Sonehara. Fast Watermark Detection Scheme for Camera-equipped Cellularphone[C]. In Proceedings of the 3rd International Conference on Mobile and Ubiquitous multimedia.2004: 101~108.
[2]Anu Pramila, Anja Keskinarkaus, TapioSepp?nen. Reading Watermarks from Printed Binary Images witha Camera Phone[C]. in Proc. of IWDW, Guildford, UK, 2009:227~240.
[3]Anu Pramila, Anja Keskinarkaus, TapioSepp?nen. Toward an Interactive Poster Using Digital Watermarking and a Mobile Phone Camera[J].Signal, Image and Video Processing, 2012,6:211~222.
[4]Anu Pramila, Anja Keskinarkaus, Valtteri Takala, TapioSepp?nen. Extracting Watermarks from Printouts Captured with Wide Angles Using Computational Photography[J].Multimedia Tools and Applications 2017,76(15):16063~16084.
[5]Han Fang, Weiming Zhang, Hang Zhou, Hao Cui, Nenghai Yu. ScreenShooting Resilient Watermarking[J]. IEEE Transactions on Information Forensicsand Security,201814,(06): 1403~1418.
[6]Wentong Chen, Na Ren, Changqing Zhu, Qifei Zhou, TapioSepp?nen, Anja Keskinarkaus. Screen- Cam Robust Image Watermarking with Feature-based Synchronization[J]. Applied Sciences,2020, 10(21): 7494.
[7]WentongChen,NaRen,ChangqingZhu,TapioSepp?nen,AnjaKeskinarkaus,QifeiZhou.JointImage EncryptionandScreencamRobustTwoWatermarking Scheme[J]. Sensors, 2021, 21(3):701.
[8]Li Li, Rui Bai, Shanqing Zhang, Chin-Chen Chang, MengtaoShi. Screen-Shooting Resilient Watermarking Scheme via Learned Invariant Keypoints and QT[J]. Sensors, 2021, 2119:6554.
[9]David Gugelmann, David Sommer, Vincent Lenders, Markus Happe, Laurent Vanbever. Screen Watermarking for Data Theft Investigation and Attribution[C].In201810th International Conference on Cyber Conflict (CyCon). IEEE, 2018:391~408.
[10]Jiren Zhu, Russell Kaplan, Justin Johnson, Li Fei- Fei. Hidden: Hiding Data with Deep Networks[C]. In Proceedings of the European Conference on ComputerVision (ECCV),2018:657~672.
[11]Jun Jia ,Zhongpai Gao, Kang Chen, Menghan Hu, Xiongkuo Min, GuangtaoZhai, XiaokangYang. RIHOOP: Robust Invisible Hyperlinks in Offline and Online Photographs[J].in IEEE Transactions on Cybernetics, doi: 10.1109/TCYB.2020.3037208.
[12]Eric Wengrowski and Kristin Dana. Light Field Messaging With Deep Photographic Steganography[J].ComputerVisionFoundation/ IEEE,2019: 1515~1524.
- END -